
У цій статті мова піде про DDoS-атаках на рівні додатків, як про один з найбільш руйнівних способів, за допомогою якого можна вивести з ладу сучасні архітектури мікро-служб.
Автори: Scott Behrens і Bryan Payne
Вступ
У цій статті мова піде про DDoS-атаках на рівні додатків, як про один з найбільш руйнівних способів, за допомогою якого можна вивести з ладу сучасні архітектури мікро-служб. Спеціально створена DDoS атака рівня додатків дозволяє каскадно вивести з ладу системи, використовуючи набагато менший обсяг ресурсів у порівнянні з тими ресурсами, які необхідні для проведення традиційних DDoS атак. Подібний розклад можливий через складні взаємозв'язків, що існують між додатками. Традиційні DDoS атаки націлені на виснаження ресурсів системи на мережевому рівні. На рівні додатків увага зосереджена на ресурсовитратності API-виклики і взаємозв'язках, щоб спровокувати атаку системи на саму себе, і іноді з лавиноподібним ефектом. У сучасній архітектурі мікро-служб подібних підхід може виявитися особливо руйнівним.
Зловмисник може створити витончені шкідливі запити, що імітують легітимний трафік, який буде проходити через всі захисні системи, в тому числі і WAF (web application firewall; фаєрвол для веб-додатків).
У цій замітці ми поговоримо про методи компанії Netflix, використовуваних для ідентифікації, тестування і захисту від DDoS-атак на рівні додатків. Почнемо з базових відомостей, що стосуються цієї проблеми. Далі поговоримо про інструменти та методи для тестування наших систем. В кінці розглянемо кроки для створення систем, які більш стійкі до DDoS атакам подібного роду.
Передісторія питання
згідно звіту компанії Akamai, DDoS атаки на рівні додатків займають менше 1% серед всіх DDoS атак. Однак ця метрика не відображає ступінь впливу подібних атак. Коли зловмисник витрачає час на підготовку плану DDoS-атаки, ефективність цього сценарію зростає в рази. З огляду на цей факт, при захисті від подібного типу атак в першу чергу необхідно переконатися, що не відбудеться вихід з ладу систем лавиноподібним чином.
Традиційні DDoS атаки на рівні додатків були засновані на попередній підготовці вхідних параметрів з урахуванням можливостей системи по генерації вихідних даних. Подібні сценарії засновані на використанні ресурсовитратності викликів (наприклад, запитів до баз даних або операції з дисковими системами) з метою надмірного використання додатка до тих пір, поки не припиниться обслуговування легітимних користувачів. А оскільки архітектура додатка є частиною більш складних і розподілених систем, у нас з'являється додаткова задача по перевірці служб і складних залежностей мікрослужб, які можуть постраждати, якщо один ключовий сервіс стає нестабільним.
Мікрослужби і DDoS
У сучасній архітектурі мікрослужб DDoS атака на рівні додатків може стати особливо ефективною, якщо ставиться завдання щодо виведення з ладу цієї служби. Щоб зрозуміти чому, розглянемо приклад мікрослужби, що використовує шлюз для взаємодії з декількома мікрослужбамі на середньому рівні і бекенда, як показано на малюнку нижче.
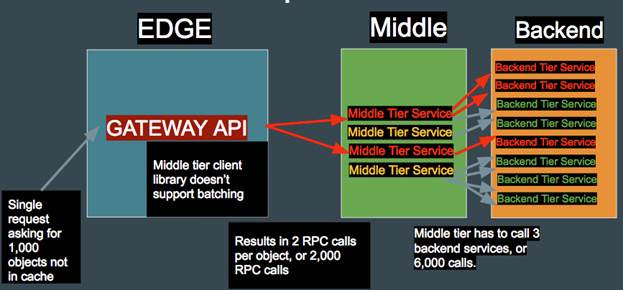
Малюнок 1: Схема взаємодії мікрослужб на різних рівнях
На діаграмі вище показано, як один запит в шлюзі може перетворитися в тисячі запитів на середньому рівні і бекенда. Якщо зловмисник зможе знайти API-виклики, які призводять до подібного ефекту, то далі можна використовувати цю фішку проти всієї системи. Якщо результуючі обчислення будуть споживати дуже багато ресурсів, деякі служби на середньому рівні можуть зупинитися. У підсумку, в залежності від рівня критичності цих служб, вся система піддасться загрозу в тій чи іншій мірі.
Подібна схема можлива завдяки архітектурі мікрослужб, яка дозволяє зловмисникові серйозно посилити атаку проти внутрішніх систем. Тобто один запит до мікрослужбе може згенерувати десятки тисяч складних викликів до служб на серединному рівні і бекенда.
Цей факт додає головного болю фахівця з безпеки. Якщо у вашому середовищі використовується WAF, налаштований стандартним чином (наприклад, як API-шлюз), то в такому режимі можуть пропускатися запити, спеціально спрямовані для виходу з ладу служб на серединному рівні і бекенда. Фаєрвол може «не здогадуватися» про наслідки одного запиту, спрямованого до вищезазначених служб, і як результат досягнуто не спрацює фільтр по чорному списку, що може привести до плачевних наслідків.
Нам, фахівцям з безпеки, важливо розуміти, як знайти виклики, які потенційно можуть використовуватися в DDoS атаках на рівні додатків.
Фреймворк для пошуку і перевірки на предмет DDoS атаки на рівні додатків
Ми повинні знайти запити, які вимагають багато ресурсів від служб на серединному рівні і бекенда. Один способів виявлення - вимір часу виконання API-викликів. Найпростіший і не дуже надійний спосіб - ідентифікація API-викликів через браузер. Відкриваємо консоль Chrome Developer, вибираємо вкладку Network, виставляємо прапорець Preserve log і далі починаємо переглядати сайт. Через деякий час сортуємо запити по колонці Time і дивимося виклики з найбільшим часом виконання. Ви отримаєте таблицю, схожу з тією, яка показана на малюнку нижче.
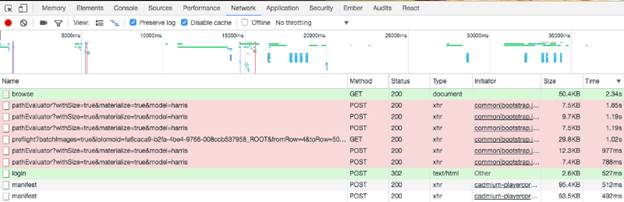
Малюнок 2: Запити сайту, відсортовані в порядку убування за часом виконання
Ця техніка може призвести до помилкових спрацьовувань, включаючи запити, які не можна модифікувати для збільшення часу виконання. Або можна пропустити виклики, які можна змінити для збільшення часу виконання. Більш точна техніка пов'язана з моніторингом періодичності запитів до служб серединного рівня. Як тільки на серединному рівні виявлена служба, яка використовує виклики з великим часом виконання, потрібно реконструювати запит, який може пройти через API-шлюз для повторного виконання запиту до знайденої службі.
Після знаходження декількох цікавих API-викликів наступний крок - інспекція вмісту цих функцій. Наше завдання - зробити так, щоб ці виклики стали споживати більше ресурсів. Одна з технік - збільшення діапазону запитуваних об'єктів. Наприклад, на зображенні нижче можна модифікувати параметри from і to для збільшення навантаження на служби серединного рівня. 
Малюнок 3: Вміст одного із запитів, який потенційно може навантажити службу
Якщо копнути ще глибше, то найчастіше можна знайти багато інших елементів запиту для збільшення споживання ресурсів. На малюнку нижче показаний приклад модифікації поля запитуваної об'єкта, діапазону і навіть розміру картинки. 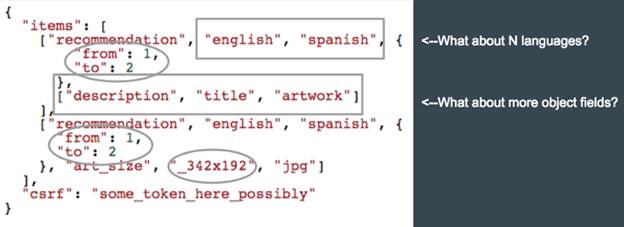
Малюнок 4: Потенційні місця запитуваної об'єкта, які можна змінити
Крім того, ви можете сформувати список індикаторів, що відображають успішність тестування, і які інформують вас про те, що тестування знаходиться в процесі виконання і місця збільшення / зменшення масштабу. Зазвичай індикатори включають в себе статусні HTTP-коди і час виконання окремих запитів під час тестування, але можуть використовуватися і інші показники: заголовки, текст відповіді, вміст стека і т. Д. На малюнку нижче показаний приклад переліку індикаторів:
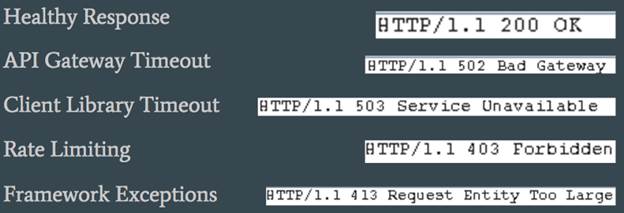
Малюнок 5: Перелік показників, які використовуються під час тестування
Ще один корисний індикатор успішності тесту - збільшений час виконання (наприклад, HTTP-код 200 і час відповіді 10 секунд). Ви можете виміряти час виконання під час тестування або коли інші користувачі використовують додаток. Як тільки ви знайшли типи запитів, які призводять до збільшення неактивності і сформували індикатори успішності тестування, необхідно переналаштувати тести з урахуванням WAF, якщо такий використовується в середовищі.
Ідеальний обсяг трафіку повинен бути нижче, ніж допустимий поріг, коли фаєрвол починає блокування, але достатній, щоб набір запитів і кількість споживаних ресурсів вивели службу з ладу.
Фреймворк Repulsive Grizzly 
Для полегшення проведення тестування в невеликих масштабах ви можете використовувати фреймворк Repulsive Grizzly , Який підтримується компанією Netflix в рамках експериментального проекту з відкритим вихідним текстом. Вихідні тексти публікуються в якості доказу нашої концепції без гарантії подальшої підтримки протягом тривалого часу. Цей фреймворк написаний на Python з використанням бібліотеки eventlet для підтримки більш високої узгодженості. Також є підтримка циклічного перебору аутентифікаційних об'єктів, що може стати в нагоді при обході деяких видів WAF'ов.
Фреймворк Repulsive Grizzly не допомагає у виявленні вразливостей, які допомагають здійснити DDoS атаку на рівні додатків. Як і у випадку з усіма іншими утилітами, пов'язаними з тестуванням безпеки, важливо не забувати використовувати ці інструменти тільки там, де дозволено. Спочатку вам потрібно знайти потенційні проблеми, згадані вище. Як тільки у вас з'явився «матеріал» для тестування, фреймворк Repulsive Grizzly спростить увесь інший процес.
Більш детальна інформація щодо використання фреймворка Repulsive Grizzly вказана в документації .
Фреймворк Cloudy Kraken
Після тестування гіпотез в невеликих масштабах можна переходити до масштабування за допомогою фреймворка Cloudy Kraken , Який працює на базі платформи Amazon Web Services (AWS). Як і у випадку з фреймворком Repulsive Grizzly, Cloudy Kraken представлений в якості експериментального проекту з відкритим вихідним кодом.
Cloudy Kraken допомагає підтримувати глобальний набір екземплярів тестування, а Repulsive Grizzly відповідає за механіку всередині кожного примірника. Також цей фреймворк створює і розподіляє тестову конфігурацію і використовує розширені мережеві драйвера сервісу AWS EC2. Cloudy Kraken дозволяє масштабувати тестування серед кількох регіонів і підтримує синхронізацію за часом для агентів, запущених паралельно. На діаграмі нижче показана загальна схема роботи Cloudy Kraken: 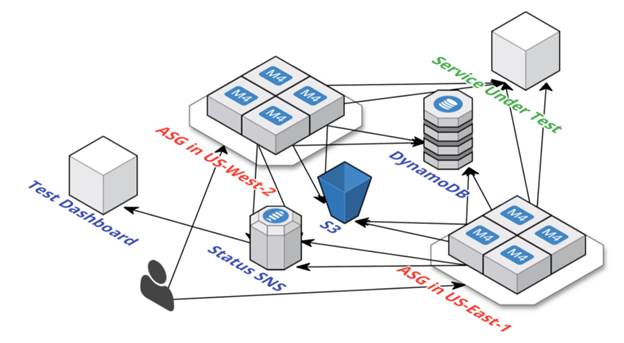
Малюнок 6: Архітектура фреймворка Cloudy Kraken
Cloudy Kraken організовує ваші тести в зрозумілій і дружній формі. Все починається з конфігураційних скриптів, що визначають логіку тестування. Потім створюється AWS-середовище для тестування і запуску примірників. Поки проводиться тестування, Cloudy Kraken збирає інформацію за допомогою служби AWS SNS. В кінці тестування AWS-ресурси знищуються. Вся послідовність кроків показана на діаграмі нижче. 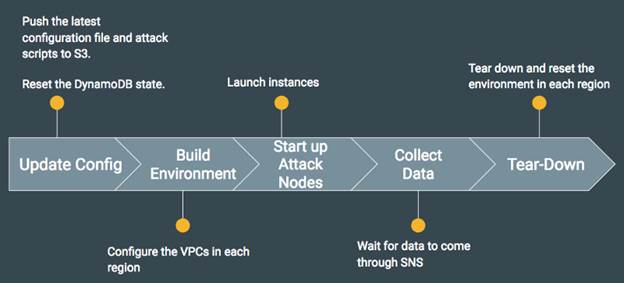
Малюнок 7: Послідовність кроків для настройки розподіленого тестування
Приклад з життя
Фахівці компанії Netflix вирішили протестувати знахідки на прикладі певного API-виклику, який був ідентифікований як повільний. Під час заходу під кодовою назвою Chaos Kong (Коли Netflix евакуювала цілий AWS-який регіон, люб'язно перенаправивши купівельний трафік в інші регіони), ми проводили тестування в промисловому середовищі в евакуйованому регіоні. Можливість протестувати сценарій DDoS атаки рівня додатків в такого роду середовищі надається досить рідко. Наша унікальна культура сподвигает нас на героїчні вчинки, і ми, скориставшись цією свободою, запустили тестування в робочому середовищі з метою зрозуміти ступінь впливу наших дій.
Тест, який ми проводили, складався з двох атак протягом 5 хвилинних інтервалів. Після закінчення тесту з'ясувалося, що в API-шлюзі ймовірність появи помилки дорівнює 80% в тому регіоні, де здійснювалася перевірка. Користувачі, які виконували запити до API-шлюзу, спостерігали помилки на сайті і інші виключення, які заважали подальшого використання сайту. На графіку нижче показані два сплеску, що відображають статусні коди з номером 503 (фіолетового кольору), які корелюють зі станом API-шлюзу.
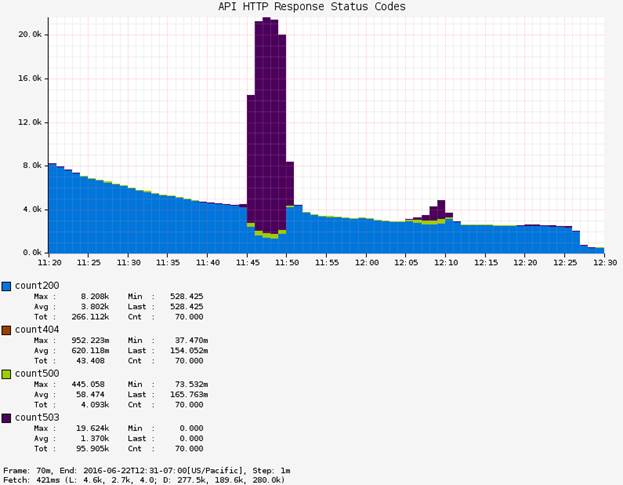
Малюнок 8: Показники тестування
Захист від DDoS атак рівня додатків
Перший і найважливіший метод - розуміння того, як працює ваша система. Ви повинні розуміти, які мікрослужби впливають на кожен аспект, пов'язаний досвідом взаємодії з покупцями / замовниками вашої системи (у випадку з останнім прикладом, користувачами сайту). Спробуйте скоротити кількість взаємозалежностей з цими службами. Якщо одна служба стає недоступною, інші мікрослужби повинні продовжувати свою роботу (можливо, в більш нестабільному стані).
Важливо мати хороше розуміння про черговість роботи служб і про механіку запитів. Можливо, на серединному рівні і бекенда слід обмежити розмір черги або розмір запитуваних об'єктів, що можна зробити як в коді клієнта, так і на рівні API-шлюзу. Установка обмежень на обсяг дозволених запитів може значно знизити ймовірність реалізації подібних атак.
Ми також рекомендуємо використовувати зворотний зв'язок, коли від служб серединного рівня і бекенда відсилаються повідомлення до WAF. Ця схема допоможе повідомити WAF про те, коли блокувати подібного роду атаки. У багатьох випадках WAF здійснює тільки моніторинг прикордонної зони і може не здогадуватися про вплив одного запиту на API-шлюз. Бажано також, щоб WAF моніторив промахи кешу (cache miss). Якщо API-шлюз постійно виконує виклик служб на серединному рівні через промахи кешу, значить, кеш налаштований некоректно або здійснюються шкідливі дії.
API-шлюзи та інші мікрослужби повинні віддавати пріоритет аутентифікаційних трафіку в порівнянні з неаутентіфікаціонним, оскільки від зловмисника потрібно більше ресурсів і майстерності для використання аутентифікаційних сесій. Цей метод також допомагає скоротити вплив DDoS атак на рівні додатків на ваших покупців.
Нарешті, переконайтеся, що використовуються розумні значення тайм-аутів в клієнтських бібліотеках і переривники ланцюгів . При використанні розумних тайм-аутів і постійному тестуванні ви зможете захистити служби середнього рівня від DDoS атак рівня додатків.
посилання
Repulsive Grizzly
Cloudy Kraken
Netflix Security Youtube Channel
