
- типи алгоритмів
- Відновлення після помилок
- Відновлення в режимі паніки
- Відновлення на рівні фрази
- продукції помилок
- різновиди компіляторів
- фази компіляції
- угруповання фаз
- Інструментарій для створення компіляторів
- Класифікація формальних граматик по Хомського
- Породження (висновок)
- Переклад (трансляція)
- Схема синтаксично керованого перекладу (СУ-схема)
- транслюють граматики
- Атрибутних граматики і трансляція
- синтаксичний аналіз
- Метод рекурсивного спуску
- Нерекурсивний предіктивне аналіз
- Безлічі FIRST і FOLLOW
- Висхідний синтаксичний аналіз
- Генератори лексичних і синтаксичних аналізаторів
- Створення лексичного аналізатора (сканера) за допомогою gplex
- Створення синтаксичного аналізатора за допомогою gppg
- ПО для розробки аналізаторів
- література
Одним з центральних понять в інформатиці є формалізує обробка інформації, звана парсинга. На її вході є невідповідний для подальшої обробки інформації текст. Це може бути текст або іншою мовою (на іншому рівні мови), або недостатньо або зовсім не формалізований текст, непридатний для простої автоматичної обробки.
Синтаксичний аналіз, парсинг - це процес зіставлення лінійної послідовності лексем (слів, фраз) мови з його формальної граматикою. Результатом зазвичай є дерево розбору (синтаксичне дерево). Зазвичай застосовується спільно з лексичним аналізом. Синтаксичний аналізатор (парсер) - це програма або частина програми, що виконує синтаксичний аналіз, тобто розпізнавання вхідної інформації. При цьому вхідні дані перетворюються до вигляду, придатного для подальшої обробки. Цей вид зазвичай являє собою формальну модель вхідної інформації на мові подальшого процесу обробки інформації.
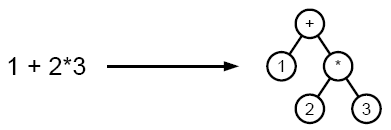
Приклад розбору виразу в дерево
При парсінгу вихідний текст перетворюється в структуру даних, зазвичай - в дерево, яке відображає синтаксичну структуру вхідної послідовності і добре підходить для подальшої обробки.
Як правило, результатом синтаксичного аналізу є синтаксична структура пропозиції, представлена або у вигляді дерева залежностей, або у вигляді дерева складових, або у вигляді деякої комбінації першого і другого способів подання.
Все що завгодно, що має "синтаксис", піддається автоматичному аналізу:
- мови програмування - розбір вихідного коду мов програмування, в процесі трансляції (компіляції або інтерпретації);
- структуровані дані - дані, мови їх опису, оформлення і т. д., наприклад, XML, HTML, CSS, ini-файли, спеціалізовані конфігураційні файли і т. п.
- SQL-запити (DSL-мову)
- математичні вирази
- регулярні вирази (які, в свою чергу, можуть використовуватися для автоматизації лексичного аналізу)
- формальні граматики
- лінгвістика - людські мови, наприклад, машинний переклад і інші генератори текстів.
типи алгоритмів
Спадний парсер (англ. Top-down parser) - такий парсер, в якому продукції граматики розкриваються, починаючи зі стартового символу, до отримання необхідної послідовності лексем.
Висхідний парсер (англ. Bottom-up parser) - такий парсер, в якому продукції відновлюються з правих частин, починаючи з токенов-лексем і закінчуючи стартовим символом.
Відновлення після помилок
Найпростіший спосіб реагування на некоректну вхідні ланцюжок лексем - завершити синтаксичний аналіз і вивести повідомлення про помилку. Однак часто виявляється корисним знайти за одну спробу синтаксичного аналізу якомога більше помилок. Саме так поводяться транслятори більшості поширених мов програмування.
Таким чином перед обробником помилок синтаксичного аналізатора стоять наступні завдання:
- він повинен ясно і точно повідомляти про наявність помилок;
- він повинен забезпечувати швидке відновлення після помилки, щоб продовжувати пошук інших помилок;
- він не повинен істотно сповільнити обробку коректної вхідний ланцюжка.
Нижче описані найбільш відомі стратегії відновлення після помилок.
Відновлення в режимі паніки
При виявленні помилки синтаксичний аналізатор пропускає вхідні лексеми по одній, поки не буде знайдена одна з спеціально певної множини синхронізуючих лексем. Зазвичай такими лексемами є роздільники, наприклад,;,) або}. Набір синхронізуючих лексем повинен визначати розробник аналізованого мови. При такій стратегії відновлення може виявитися, що значна кількість символів будуть пропущені без перевірки на наявність додаткових помилок. Дана стратегія відновлення найбільш проста в реалізації.
Відновлення на рівні фрази
Іноді при виявленні помилки синтаксичний аналізатор може виконати локальну корекцію вхідного потоку так, щоб це дозволило йому продовжувати роботу. Наприклад, перед крапкою з комою, яка відділяє різні оператори в мові програмування, синтаксичний аналізатор може закрити всі ще не закриті круглі дужки. Це більш складний в проектуванні і реалізації спосіб, однак, в деяких ситуаціях, він може працювати значно краще відновлення в режимі паніки. Природно, дана стратегія безсила, якщо справжня помилка сталася до точки виявлення помилки синтаксичним аналізатором.
продукції помилок
Знання найбільш поширених помилок дозволяє розширити граматику мови продукціям, породжують помилкові конструкції. При спрацьовуванні таких продукцій реєструється помилка, але синтаксичний аналізатор продовжує працювати в звичайному режимі.
різновиди компіляторів
Що таке компілятор. Вихідний і мову перекладу.
- інтерпретатори
- форматування тексту
- Статичні аналізатори коду
- препроцесори
- макроси define
- включення файлів #include
- умовна компіляція #ifdef
- розширення мови, які препроцесор переводить в код на мові
фази компіляції
- Лексичний аналіз (сканування)
- Синтаксичний аналіз (розбір, "парсинг")
- семантичний аналіз
На прикладі вираження p: = i + r * 60
id1: = id2 + id3 * 60
- Виявлення помилок. Лексичні, синтаксичні та семантичні помилки.
- Генерація проміжного коду
На прикладі трьохадресних коду
t1: = IntToReal (60) t2: = id3 * t1; t3: = id2 + t2; id1: = t3;
- оптимізація коду
t1: = id3 * 60.0; id1: = id2 + t1;
- Генерація коду (основне - призначення змінних регістрів)
MOVF id3, R2 MULF # 60.0, R2 MOVF id2, R1 ADDF R2, R1 MOVF R1, id1 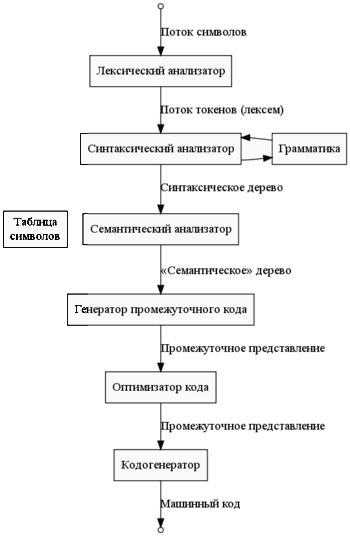
Майже на кожній стадії можуть виконуватися додаткові оптимізації, а також відбувається аналіз і обробка помилок.
Математичним забезпеченням фаз лексичного і синтаксичного аналізу є теорія формальних мов. Зазвичай лексичні аналізатори генеруються за допомогою регулярних виразів.
Синтаксичний аналіз ґрунтується на теорії контекстно-вільних (КС) граматик. Загальна форма КС-граматики не дозволяє розбирати мову досить простим (зокрема, автоматично згенерували) парсером, тому мови програмування зазвичай належать одному з декількох спеціальних підкласів КС-мов (LL, LR, LALR), які простіше розбирати і деякі з яких будуть детально вивчені в курсі.
Згадані досягнення теорії формальних мов налічують вже кілька десятків років, і в цій області не очікується будь-яких нових розробок, тим більше що наявні теоретичні результати добре вирішують практичні завдання. Інакше йде справа з вивченням інших двох розділів компіляції: семантичним аналізом і оптимізацією. Роботи по формальному опису семантики мов програмування інтенсивно з'являлися в 70-80-х роках. Однак жодна з побудованих теорій не увійшла в широкий ужиток при побудові компіляторів, і сьогодні справа йде таким чином, що семантика спочатку описується природною мовою, а потім реалізується в компіляторі великим набором вручну закодованих умовних операторів.
Навпаки, в останні роки зростає актуальність теорії оптимізують перетворень - це пояснюється появою все більш високорівневих мов і різноманітних апаратних платформ. Оптимізація також вимагає залучення розвиненого математичного апарату (зокрема, для вирішення питання про коректність перетворень). Багато з досягнень активно впроваджуються в промислові компілятори. Все більше це стосується перетворень, пов'язаних з розпаралелюванням.
На етапі побудови семантичного дерева будується таблиця символів - в неї заносяться імена, які були присутні в початковому тексті, до них додаються такі атрибути як тип, відведена пам'ять, область видимості.
угруповання фаз
- Front-end і back-end компілятори.
Перераховані вище фази зазвичай групуються в два модуля - front-end і back-end, в залежності від того, до якої сторони процесу компіляції вони ближче, до вихідного мови або до машинного коду для цільової платформи, відповідно. Можливість окремо розробляти front-end і back-end підвищує ефективність праці розробників компіляторів - наскільки, залежить від ефективності використовуваного внутрішнього уявлення, що зв'язує ці два модуля. Останнім часом все частіше виділяють middle-end - частини компілятора, які активно працюють з проміжним поданням.
- Проходи. Угруповання фаз компілятора в проходи (наприклад, об'єднання фаз лексичного, синтаксичного, семантичного аналізу і генерації коду).
Розбиття процесу компіляції на фази є логічним. Є й інший, фізичний підхід до такого розбиття - на проходи. Проходом зазвичай вважається одне читання вихідного потоку (і, можливо, одна закінчена генерація вихідного). Різні фази можуть групуватися в один прохід.
- Зменшення кількості проходів (на прикладі попереднього опису підпрограм). Технологія зворотних поправок.
Компіляція і багатомодульні. Необхідність компілювати модуль в певний формат, що містить правильну програму. Переміщувані адреси. Редактор зв'язків (лінковщік).
Інструментарій для створення компіляторів
- Генератори лексичних аналізаторів (сканерів)
- Генератори синтаксичних аналізаторів (парсеров)
- Автоматичні генератори коду
компілятори компіляторів
- Lex + Yacc
- Flex + Bison
- CoCo
- Antlr
- Gold Parser Builder
- GPLex + GPPG
породжують граматики
Визначення. Термінали, нетермінали, символи. Продукції. Стартовий символ.
позначення:
a, b, c, ... - термінали u, v, w, x, y, z - рядки (ланцюжки) терміналів A, B, C, ... - нетермінали α, β, γ, ... - рядки (ланцюжки) нетерміналів і терміналів ε - порожній ланцюжок
Опр. формальної граматики (граматики Хомського)
G = (N, Σ, P, S) N - нетермінали Σ - термінали P - правила виведення (продукції) виду α → β, α - непорожня
V = Σ + N - безліч всіх нетерміналів і терміналів
V * - множина всіх ланцюжків символів з V
V + = V * - {ε}
Класифікація формальних граматик по Хомського
- Граматика типу 0 (загального виду). Правила мають вигляд α → β
- Граматика типу 1 (контекстно залежна, КЗ)
Правила мають вигляд αAβ → αγβ. γ належить V +, тобто граматика є неукорачівающей α, β називаються лівим і правим контекстом
- Граматика типу 2 (контекстно вільна, КС)
Правила мають вигляд A → α. α належить V *, тобто граматика може бути вкорочують => КС мови не містяться в КЗ Найбільш близька до БНФ
- Граматика типу 3 (автоматна, регулярна)
Правила мають вигляд A → aB, A → a, A → ε Автоматні мови містяться в КС мовами
Приклад. Граматика, що породжує мову правильних дужкових виразів.
S → (S) | SS | ε
Породження (висновок)
позначення
=> => + (1 або більше) => * (0 або більше)
Сентенціальной форма граматики - це рядок, яка може бути виведена зі стартового символу.
Пропозиція (сентенція) граматики - це сентенціальной форма, що складається з одних терміналів.
Мова L (G) граматики - це безліч всіх її пропозицій.
позначення:
=> (Lm) => (lm) * => (rm) +
Лівий, правий висновок (породження).
приклад
E → E + T | T T → T * P | P P → i | (E)
Лівий і правий висновок для пропозиції i + i * i
Дерево виведення (синтаксичне дерево, дерево розбору) рядки пропозиції. На відміну від породження, з нього виключена інформація про порядок виведення.
Крона дерева розбору - ланцюжок міток листя зліва направо
Граматика, яка дає більше одного дерева розбору для деякого пропозиції, називається неоднозначною.
Приклад неоднозначною граматики. Граматика арифметичних виразів.
E → E + E | E * E | i
Два дерева розбору для ланцюжка i + i * i
Перетворення в еквівалентну однозначну граматику:
E → E + T | T T → T * P | P P → i
Приклад неоднозначною граматики. Граматика умовного оператора
S → if b then S | if b then S else S | a
Два дерева розбору для ланцюжка if b then if b then a
Перетворення в еквівалентну однозначну граматику:
S → if b then S | if b then S2 else S | a S2 → if b then S2 else S2 | a
Затвердження. Проблема неоднозначності довільній КС-граматики алгоритмічно не розв'язна
Леворекурсівние граматики, їх проблеми. Алгоритм усунення лівої рекурсії.
Переклад (трансляція)
Раніше ми вирішували питання про приналежність деякій ланцюжка α цікавить нас мови L, що задається граматикою G. Але завдання компіляції ширше: не тільки розпізнати вхідну ланцюжок, але і згенерувати вихідну.
Визначення.
Переклад з мови L1 на мову L2 - Нехай Σ і Δ - два алфавіту (звані "вхідним" і "вихідних" відповідно). L1 ⊂ Σ *, L2 ⊂ Δ *. Перекладом з мови L1 на мову L2 називається відображення τ: L1 → L2.
Щоб вирішити зазначене завдання (тобто конструктивно визначити переклад), можна вбудувати в процес перевірки належності деякі дії, що формують на виході бажаний результат.
Схема синтаксично керованого перекладу (СУ-схема)
СУ-схема - це граматика, в яку з кожним синтаксичним правилом вбудований елемент перекладу.
Приклад. Переклад алгебраїчного виразу в полізім (польська інверсний запис). Запишемо правила граматика разом з елементами перекладу.
Правило Елемент перекладу E → E + T E = ET + E → T E = T T → T * P T = TP * T → P T = P P → (E) P = E P → <id> P = <id>
Виведемо ланцюжок a * (b + c) і одночасно переведемо її в полізім: abc + * (як зазвичай, використовуємо лівий висновок):
(E, E) ⇒ (T, T) ⇒ (T * P, TP *) ⇒ (P * P, PP *) ⇒ (a * P, a P *) ⇒ (a * (E), a E * ) ⇒ ⇒ (a * (E + T), a ET + *) ⇒ * (a * (b + c), abc + *)
Визначення.
Схема синтаксично керованого перекладу- це п'ятірка T = (N, Σ, Δ, R, S),
де:
N - безліч нетерміналів ( "змінних"), Σ - вхідний алфавіт, Δ - вихідний алфавіт, S - стартовий символ (S ε N), R = {A → (α, β) | A ε N, α ε (N ∪ Σ) *, β ε (N ∪ Δ) *}.
Причому α і β в кожному конкретному правилі містять одні й ті ж нетермінали з точністю до перестановки.
Далі вважаємо, що задана деяка СУ-схема T = (N, Σ, Δ, R, S).
Визначення.
Вхідна граматика, відповідна СУ-схемою T- це четвірка Gin = (N, Σ, R, S),
де
P = {A → α | ∃β A → (α, β) ε R}.
Визначення.
Вихідна граматика, відповідна СУ-схемою T- це четвірка Go = (N, Δ, R, S),
де
P = {A → β | ∃α A → (α, β) ε R}.
Визначення.
СУ-переклад, СУ-трансляція- це безліч {(x, y) | (S, S) ⇒ * (x, y), x ε Σ *, y ε Δ *},
позначається зазвичай τ (T).
СУ-переклад можна розуміти як трансформацію синтаксичних дерев (відповідних висновку вхідний і вихідний ланцюжків).
транслюють граматики
Дозволяють вирішувати задачу перекладу в більш складних випадках, ніж СУ-схеми. ТГ це різновид КС-граматик, де символи (термінали) розділені на два безлічі, Σi і Σa (a від action), звані "вхідними" і "операційними" відповідно. При використанні ТГ, щоб розрізняти елементи Σi і Σa, будемо укладати останні в фігурні дужки, '{', '}', вважаючи отримані на листі три символи одним символом алфавіту.
Приклад. Переклад простого алгебраїчного виразу в полізім ...
Визначення.
активна ланцюжок - Нехай α ε (Σi ∪ Σa) *. Тоді α називається активної ланцюжком. Вхідні (операційні) символи активної ланцюжка, записані окремо в тому ж порядку, як вони зустрічалися в ній, утворюють вхідні (операційну) ланцюжок.
Операційні символи можна трактувати як імена процедур, які виконують певні дії. Поки - процедур без параметрів. Операційні символи також можуть використовуватися для інтерпретації коду. Операційні символи можуть перебувати в будь-якій частині результату продукції, не тільки в суфіксі, але це може сильно ускладнити парсер (іноді доведеться відкочуватися).
Атрибутних граматики і трансляція
В АГ з кожним символом граматики може бути пов'язаний один або кілька атрибутів. Для кожного синтаксичного правила вводяться семантичні правила, що встановлюють функціональні залежності між атрибутами.
Дерево, що містить атрибути, називається анотований. Атрибути надають сенс синтаксичній структурі, описуваної деревом, і тому анотоване дерево називається також семантичним деревом.
Приклад. Обчислення простого арифметичного виразу ...
Типи атрибутів.
- Синтезовані - значення таких атрибутів залежать тільки від значень атрибутів нащадків в дереві розбору.
- Успадковані - значення таких атрибутів залежать від значень атрибутів батьківського вузла, вузлів-братів і сестер (дочірніх для батьківського), а також інших атрибутів самого вузла.
синтаксичний аналіз
Поняття синтаксичного аналізатора.
Спадні (top-down) і висхідні (bottom-up) синтаксичні аналізатори
Метод рекурсивного спуску
Інтелектуальне синтаксичний аналізатор - це синтаксичний аналізатор, який працює методом рекурсивного спуску і не вимагає відкатів.
Нерекурсивний предіктивне аналіз
Схема роботи зі стеком, таблицею розбору, вхідним буфером
Алгоритм нерекурсівние інтелектуального аналізу
приклад
Безлічі FIRST і FOLLOW
Визначення.
Приклад.
Алгоритм побудови таблиць інтелектуального аналізу.
Визначення LL (1) граматики. Пояснення назви.
Затв. LL (1) граматика не може бути леворекурсівной або неоднозначною.
Еквівалентну визначення LL (1) граматики.
Відновлення після помилок в Інтелектуальне аналізі.
Висхідний синтаксичний аналіз
Найбільш розповсюджений різновид - ПС-аналіз (перенесення-згортка - shift-reduce)
Поняття основи. Приклади.
Звернене праве породження і обрізка основ.
Стекова реалізація ПС-аналізу. Основні операції:
Перенесення (shift) Згортка (reduce) Допуск (accept) Помилка (error)
Затв. Основа завжди знаходиться на вершині стека і ніколи - всередині нього. Доведення.
Поняття активного префікса.
LR-аналізатори. SLR, канонічний LR і LALR аналізатори.
Загальна схема і алгоритм LR-аналізу. Приклад.
LR-граматики.
Неоднозначності виду shift-reduce і їх дозвіл.
Генератори лексичних і синтаксичних аналізаторів
Огляд.
Yacc, Lex Byson, Flex CoCo ANTLR Gold Parser Builder GPPG
Створення лексичного аналізатора (сканера) за допомогою gplex
Загальна структура .l файлу
Особливості .l файлу gplex
Повернення типів лексем
Лексеми ідентифікаторів, чисел.
ключові слова
позиція лексеми
Початкові стану сканера, їх зміна, використання для вирізання коментарів:
% X COMMENT %% "/ *" {BEGIN (COMMENT);} <COMMENT> "* /" {BEGIN (INITIAL);} <COMMENT> << EOF >> {Console.WriteLine ( "Коментар не закрите"); }
Створення синтаксичного аналізатора за допомогою gppg
Загальна структура .y файлу
Завдання типів лексем
Таблиця пріоритетів і асоціативності
Особливості .y файлу gppg
приклад
- найпростіший калькулятор
- Найпростіший калькулятор з пріоритетом операцій
- Створення дерева розбору програми
- Перетворення в XML
- Додавання змінних. Подання про таблиці символів
- Додавання присвоювання
- Додавання типів
- Додавання керуючих конструкцій
ПО для розробки аналізаторів
ANTLR - генератор парсеров
Bison - генератор парсеров
Coco / R - генератор сканера і парсеру
GOLD - парсер
gppg - генератор парсеров для мови C #
JavaCC - генератор парсеров для мови Java
Lemon Parser - генератор парсеров
Lex - генератор сканерів
LRgen - генератор сканерів і парсеров
PEG.js - генератор парсеров для Javascript
Jison - генератор парсеров для Javascript
Ragel - генератор вбудованих парсеров
Rats! - генератор парсеров для Java
Rebol
SableCC - генератор інтерпретаторів
Spirit Parser Framework - генератор парсеров
Xerces - XML парсер
Yacc - генератор парсеров
SHProto - генератор FSM-парсеров
AGFL - генератор парсеров природної мови
література
- Ахо А., Мережі Р., Ульман Д. Компілятори. Принципи, технології, інструменти. - М .: Вільямс, 2001..
- Карпов Ю. Г. Основи побудови трансляторів. - М .: BHV, 2005.
- Свердлов С. З. Мови програмування і методи трансляції. - М .: Питер, 2007.
- Опальова Е. А., Самойленко В.П. Мови програмування і методи трансляції. - М .: BHV, 2005.
- Альфред В. Ахо, Моніка С. Лам, Рави Мережі, Джеффрі Д. Ульман. Компілятори: принципи, технології та інструментарій = Compilers: Principles, Techniques, and Tools. - 2-е вид. - М .: Вільямс, 2008. - ISBN 978-5-8459-1349-4
- Робін Хантер Основні концепції компіляторів = The Essence of Compilers. - М .: "Вільямс", 2002. - С. 256. - ISBN 5-8459-0360-2
Чи знаєте Ви,
що, коли деякі дослідники, які намагаються примирити релятивізм і ефірну фізику, кажуть, наприклад, про те, що космос складається на 70% з "фізичного вакууму", а на 30% - з речовини і поля, то вони впадають в фундаментальне логічне протиріччя. Це протиріччя полягає в наступному.
Речовина і поле не їсти щось окреме від ефіру, також як і людське тіло не є щось окреме від атомів і молекул його складових. Воно і є ці атоми і молекули, зібрані в певному порядку. Також і речовина не є щось окреме від елементарних частинок, а воно складається з них як базової матерії. Також і елементарні частинки складаються з частинок ефіру як базової матерії нижнього рівня. Таким чином, все, що є у Всесвіті - це є ефір. Ефіру 100%. З нього складаються елементарні частинки, а з них все інше. Детальніше читайте в FAQ по ефірної фізіці .
НОВИНИ ФОРУМУ 
Лицарі Теорії ефіру 20.07.2019 - 5:34: ЕКОНОМІКА І ФІНАНСИ - Economy and Finances -> КОЛЛАПС Світової Фінансової СИСТЕМИ - Карім_Хайдаров.
20.07.2019 - 5:30: ЕКОЛОГІЯ - Ecology -> Біологічна безпека населення - Карім_Хайдаров.
20.07.2019 - 5:27: ВІЙНА, ПОЛІТИКА І НАУКА - War, Politics and Science -> ЗА НАМИ страви - Карім_Хайдаров.
16.07.2019 - 10:00: ВІЙНА, ПОЛІТИКА І НАУКА - War, Politics and Science -> Расчеловечивания ЛЮДИНИ. КОМУ ЦЕ ТРЕБА? - Карім_Хайдаров.
16.07.2019 - 9:58: ВИХОВАННЯ, ОСВІТА, ОСВІТА - Upbringing, Inlightening, Education -> Просвітніцтво від О.Н. Четверикова - Карім_Хайдаров.
12.07.2019 - 17:46: ФІЗИКА ЕФІРУ - Aether Physics -> Поняття годині и ефір - Владімір_Афонін.
11.07.2019 - 7:14: ВІЙНА, ПОЛІТИКА І НАУКА - War, Politics and Science -> Проблема державного тероризму - Карім_Хайдаров.
11.07.2019 - 6:57: СОВІСТЬ - Conscience -> російський СВІТ - Карім_Хайдаров.
07.07.2019 - 9:52: НОВІ ТЕХНОЛОГІЇ - New Technologies -> ПРОБЛЕМА штучних інтелекту - Карім_Хайдаров.
03.07.2019 - 5:38: ВИХОВАННЯ, ОСВІТА, ОСВІТА - Upbringing, Inlightening, Education -> Просвітніцтво від В'ячеслава Осієвського - Карім_Хайдаров.
27.06.2019 - 10:01: Сейсмологи - Seismology -> Запаси води під Землею - Карім_Хайдаров.
27.06.2019 - 10:00: ЕКОЛОГІЯ - Ecology -> ПРОБЛЕМА прісної води - Карім_Хайдаров. ![]()
