
- 1. У чому проблема
- 2. Тестовий складовою індикатор
- 3. Напрями вирішення проблеми
- 4. Зменшуємо кількість барів
- 5. Зменшуємо кількість буферів
1. У чому проблема
Вам, напевно, доводилося використовувати або створювати радники або індикатори, які для своєї роботи використовують кілька інших допоміжних індикаторів.
Такий складовою індикатор фактично еквівалентний декільком простим. Наприклад, згаданий MACD витрачає пам'яті і процесорного часу в три рази більше, ніж один EMA, оскільки терміналу доводиться виділяти пам'ять для буферів головного індикатора і для буферів всіх його допоміжних індикаторів.
Крім MACD, є і більш складні індикатори, в яких задіяні не два, а кілька допоміжних індикаторів.
Більш того, ці витрати зростають ще в рази, якщо:
- цей індикатор мультітаймфреймовий (наприклад, відстежує збіг хвиль на кількох ТФ), на кожен ТФ йому доводиться створити окремі копії допоміжних індикаторів;
- цей індикатор мультивалютний;
- трейдер за допомогою цього індикатора торгує на декількох валютних парах (знаю трейдерів, у яких кількість одночасно торгуються пар перевалює за два десятка).
Поєднання цих умов здатне приводити до елементарної нестачі оперативної пам'яті на комп'ютері (знаю реальні випадки, коли через подібні індикаторів термінал вимагав гігабайти пам'яті). В MetaTrader брак пам'яті виглядає так:
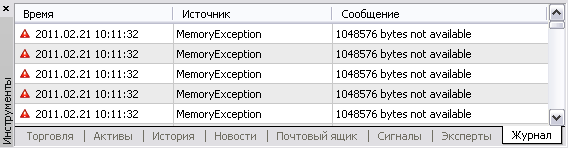
Термінал в такій ситуації просто не зможе помістити індикатор на графік або некоректно його розрахує (якщо в коді індикатора не передбачена обробка помилки виділення пам'яті), а то і зовсім закриється.
У більш вигідному випадку недолік оперативної пам'яті комп'ютера вдається компенсувати використанням великого обсягу віртуальної пам'яті, тобто зберіганням частини пам'яті на жорсткому диску. Всі програми будуть працювати, але дуже повільно ...
2. Тестовий складовою індикатор
Щоб продовжити наші дослідження в рамках даної статті більш конкретно, давайте створимо який-небудь складовою індикатор, більш складний, ніж MACD.
Нехай це буде індикатор, який ловить зародження трендів. Він буде підсумовувати сигнали відразу з 5 таймфреймів, наприклад: H4, H1, M15, M5, M1. Це дозволить йому ловити резонанс великих і маленьких зароджуються трендів, що має підвищити надійність прогнозу. Як джерела сигналів на кожному таймфрейме виступатимуть індикатори Ichimoku і Price_Channel , Що входять в поставку MetaTrader 5 :
- по Ichimoku будемо вважати ознакою висхідного тренда знаходження лінії Tenkan (червона) вище лінії Kijun (синя), спадного тренда - навпаки;
- по Price_Channel висхідний тренд - якщо ціна вище середньої лінії, спадний - якщо нижче.
Разом наш індикатор буде використовувати 10 допоміжних індикаторів: 5 таймфреймів по 2 індикатора. Назвемо наш індикатор Trender.
Ось його повний вихідний код (також він прикладений до статті):
Використовувати цей індикатор потрібно на графіку з наймолодшим таймфрейме з тих, з яких він збирає сигнали, оскільки тільки так ми побачимо прояви всіх маленьких трендів. У нашому випадку молодший таймфрейме є M1. Так виглядає індикатор:
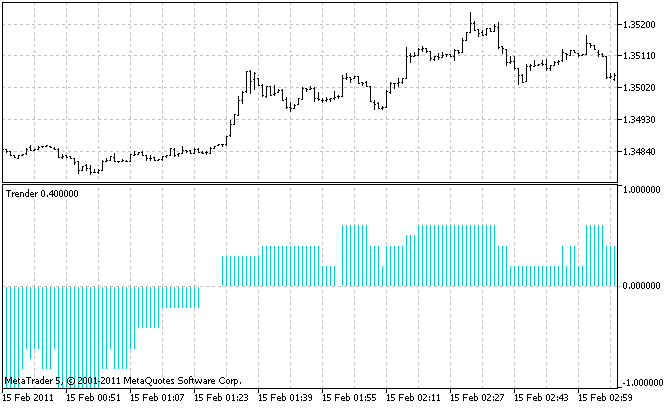
Ну і тепер перейдемо до найважливішого: підрахуємо, скільки ж пам'яті споживає такий індикатор.
Заглянемо в вихідний код індикатора Ichimoku (повний код см. В додатку):
#property indicator_buffers 5і Price_Channel (повний код см. в додатку):
#property indicator_buffers 3За цих рядках коду видно, що ці індикатори на двох створюють 8 буферів. Помножимо це на 5 таймфреймів. І додамо 1 буфер самого індикатора Trender. Разом вийде 41 буфер! Ось такі значні цифри можуть ховатися за деякими простенькими на вигляд (на графіку) індикаторами.
При стандартних налаштуваннях терміналу один буфер містить приблизно 100000 значень, кожне має тип double і займає 8 байт. Таким чином, 41 буфер - це приблизно 31 Mb пам'яті. Це тільки самі значення, я не знаю, яка ще службова інформація міститься в буферах.
"31 Mb - це не так вже й багато", - скажете ви. Але коли трейдер торгує на великій кількості пар, такі обсяги стають проблемою для нього. Крім індикаторів, самі графіки сильно пожирають пам'ять - адже, на відміну від індикаторів, кожен бар має відразу кілька значень: OHLC, час, обсяг. Як все це вмістити на одному комп'ютері?
3. Напрями вирішення проблеми
Ви можете, звичайно, спробувати встановити в ваш комп'ютер більше оперативної пам'яті. Якщо ж цей варіант вам не підходить з технічних, фінансових чи інших причин, або ви встановили максимум пам'яті, а її все одно недостатньо, то доведеться розбиратися з ненажерливими індикаторами, щоб якось скоротити їх раціон.
Для цього давайте згадаємо ... шкільну геометрію. Уявімо все буфери нашого складеного індикатора у вигляді суцільного прямокутника:
Площа цього прямокутника - це пам'ять, яку він займає. Зменшити площу можна, якщо зменшити ширину або висоту.
Ширина в даному випадку - кількість барів, на яких будуються індикатори. Висота - кількість індикаторних буферів.
4. Зменшуємо кількість барів
4.1. просте рішення Не потрібно навіть бути програмістом, щоб "покриття" настройки MetaTrader:
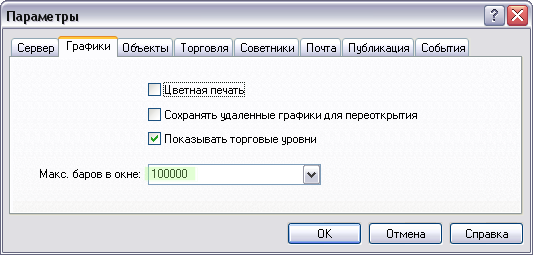
Зменшивши значення параметра «Макс. барів у вікні », ви, як наслідок, зменшіть і розмір індикаторних буферів в цих вікнах. Це просто, дуже ефективно і доступно кожному (якщо у трейдера немає потреби при торгівлі глибоко переглядати історію).
4.2. Чи є інше рішення?
MQL5-програмісти знають, що індикаторні буфери оголошуються в індикаторі як динамічні масиви без попереднього завдання розміру. Ось, наприклад, 5 буферів в тому ж Ichimoku:
double ExtTenkanBuffer []; double ExtKijunBuffer []; double ExtSpanABuffer []; double ExtSpanBBuffer []; double ExtChinkouBuffer [];Довжина масивів не вказується, оскільки в будь-якому випадку розмір цим масивів буде поставлено терміналом MetaTrader 5 на всю довжину доступною історії.
Аналогічно і в функції OnCalculate :
У ній індикатору передається цінової буфер. Пам'ять під нього вже виділена терміналом, і програміст не може вплинути на її розмір.
Крім того, MQL5 дозволяє використовувати буфер одного індикатора в якості цінового буфера для іншого (будувати " індикатор від індикатора " ). Але і тут програміст не може поставити ніяких обмежень розміру, він передає лише хендл індикатора.
Таким чином, в MQL5 не передбачено будь-яких механізмів для обмеження довжини індикаторних буферів.
5. Зменшуємо кількість буферів
Тут у програміста існує великий вибір. Я придумав кілька нескладних теоретичних способів, як зменшити кількість буферів складеного індикатора. У всіх способах, звичайно, скорочуються буфери лише допоміжних індикаторів, тому що передбачається, що в головному індикаторі все буфери нам потрібні.
Розглянемо далі ці способи докладніше і перевіримо, чи працюють вони на практиці, які мають переваги і недоліки.
5.1. Спосіб "Need"
Якщо у допоміжному індикаторі багато буферів, то може виявитися так, що не всі вони потрібні головному індикатору. Тому невикористовувані буфери можна просто відключити, щоб вони не займали пам'ять. Для цього потрібно внести зміни до початкового коду цього допоміжного індикатора.
Проробимо це з одним з наших допоміжних індикаторів - Price_Channel. У ньому три буфера, а Trender зчитує тільки один, так що є чого прибрати непотрібного.
Повний код індикаторів Price_Channel (вихідний індикатор), Price_Channel-Need (вже повністю перероблений) прикладений до статті, а далі я опишу тільки зміни, які були до нього внесені.
Насамперед зменшуємо лічильник буферів з 3 до 1:
#property indicator_buffers 1 #property indicator_plots 1 І прибираємо два зайвих буферних масиву:
Тепер, якщо спробувати скомпілювати цей індикатор, компілятор покаже всі рядки, де є звернення до цих масивів:
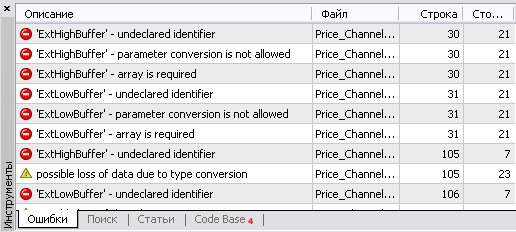
Такий прийом дозволяє швидко знайти місця, які потребують змін. Це буде дуже корисно, якщо код індикатора дуже великий.
У нашому випадку рядків з "undeclared identifier" всього 4. Давайте їх правити.
Як і слід було очікувати, дві з них знаходяться в OnInit. Але разом з ними довелося прибрати і рядок з потрібним нам ExtMiddBuffer - додавши замість неї аналогічну, але з іншим номером буфера. Адже буфера з номером 2 у індикатора тепер бути не може, а може бути тільки 0:
SetIndexBuffer (0, ExtMiddBuffer, INDICATOR_DATA);Якщо плануєте "урізаний" індикатор використовувати потім в візуальному режимі, то враховуйте, що при зміні номера буфера потрібно міняти і налаштування оформлення. У нашому випадку це:
#property indicator_type1 DRAW_LINE Якщо ж візуалізація вам не потрібна, то можна і не витрачати час на зміну оформлення - до помилок це не призводить.
Продовжимо відпрацьовувати список "undeclared identifier". Останні 2 зміни (що, знову ж таки, передбачувано) припадають на OnCalculate, де йде заповнення цих буферних масивів. Так як потрібний нам ExtMiddBuffer звертається до віддалених ExtHighBuffer і ExtLowBuffer, замість них довелося підставити проміжні змінні:
Як бачите, нічого складного у всій цій "хірургічної операції" не виявилося. Потрібні місця знайшлися швидко, всього кілька "рухів скальпелем" і - мінус два буфера. У масштабах всього складеного індикатора Trender економія складе 10 буферів (2 * 5 ТФ).
Можна відкрити один під одним Price_Channel і Price_Channel-Need і побачити зниклі зайві буфери:
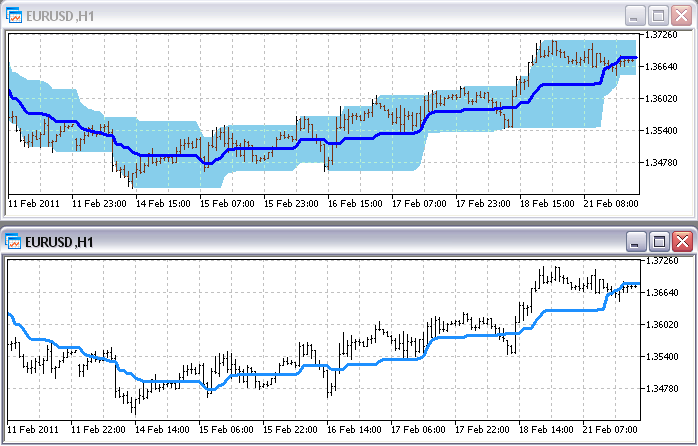
Щоб використовувати Price_Channel-Need в індикаторі Trender, треба виправити в коді Trender ім'я допоміжного індикатора з "Price_Channel" на "Price_Channel-Need", а також номер потрібного нам буфера в ньому - замість 2 тепер 0. Готовий Trender-Need прикріплений до статті.
5.2. Спосіб "Aggregate"
Якщо головний індикатор зчитує з допоміжного більше одного буфера і проводить потім з ними якийсь агрегує дію (наприклад, додавання чи порівняння), то зовсім не обов'язково проробляти цю дію саме в головному індикаторі. Можна виконати його прямо в допоміжному, а в головний індикатор віддати лише результат. Тоді відпаде необхідність в наявності декількох буферів - їх замінить один.
У нашому випадку такий спосіб можна застосувати до Ichimoku. Адже Trender використовує з нього 2 буфера (0 - Tenkan і 1 - Kijun):
CopyBuffer (h_Ichimoku [itf], 0, Time, 1, bufTenkan); double Tenkan = bufTenkan [0]; CopyBuffer (h_Ichimoku [itf], 1, Time, 1, bufKijun); double Kijun = bufKijun [0]; if (Tenkan> Kijun) Signal ++; if (Tenkan <Kijun) Signal--;Якщо в Ichimoku агрегувати 0-й і 1-й буфер в один сигнальний, то представлений вище фрагмент коду в Trender заміниться на такий:
CopyBuffer (h_Ichimoku [itf], 0, Time, 1, bufSignal); Signal + = bufSignal [0]; Повністю цей Trender-Aggregate прикладений до статті.
А тепер розглянемо ключові зміни, які потрібно внести в Ichimoku.
У цьому індикаторі є ще і невикористовувані буфери. Так що крім способу "Aggregate" заодно застосуємо і описаний раніше спосіб "Need". Таким чином, з 5 буферів в Ichimoku залишиться лише один - агрегує потрібні нам буфери:
#property indicator_buffers 1 #property indicator_plots 1 Дамо цьому єдиному буферу нове ім'я:
У новому імені є і практичний сенс: воно дозволяє видалити з коду індикатора імена всіх раніше використовувалися буферів. Це дозволить (з використанням прийому компіляції з опису способу "Need") швидко знайти всі рядки, які потрібно змінити.
Якщо ви збираєтеся візуалізувати індикатор на графіку, то не забудьте внести зміни в налаштування оформлення. А також врахуйте, що агрегує буфер в нашому випадку має інший діапазон значень, ніж поглинені їм два буфера. Він показує тепер не цінову похідну, а який з двох буферів більше. Відображати такі результати зручніше в окремому віконці внизу графіка:
#property indicator_separate_windowОтже, вносимо зміни в OnInit:
SetIndexBuffer (0, ExtSignalBuffer, INDICATOR_DATA); І найцікавіше - в OnCalculate. Зверніть увагу: три непотрібних буфера просто видаляємо (ми ж застосовуємо і спосіб "Need"), а потрібні нам ExtTenkanBuffer і ExtKijunBuffer замінюємо тимчасовими змінними Tenkan і Kijun. Ці змінні і використовуються в кінці циклу для розрахунку нашого агрегує буфера ExtSignalBuffer:
Разом - мінус 4 буфера. А якби ми застосували до Ichimoku тільки спосіб "Need", то було б лише мінус 3.
В рамках всього Trender наша економія склала 20 буферів (4 * 5 ТФ).
Повний код Ichimoku-Aggregate прикладений до статті. Щоб подивитися, як виглядає цей індикатор в порівнянні з оригіналом, відкриємо їх обидва на одному графіку. Змінений індикатор, як ви пам'ятаєте, виводиться тепер в нижній частині графіка в окремому вікні:
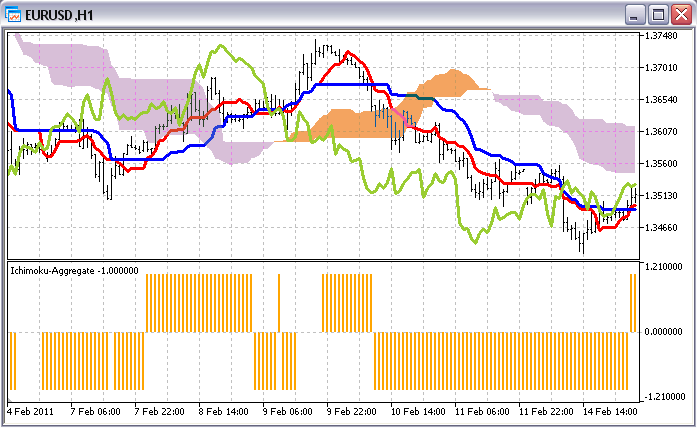
5.3. Спосіб "Include"
Самий кардинальний спосіб зменшити кількість буферів - це взагалі позбутися від допоміжних індикаторів. Тоді в нашому складеному індикаторі залишиться всього 1 буфер, що належить головному індикатору. Менше вже нікуди.
Досягти такого результату можна, якщо перенести код допоміжних індикаторів в головний індикатор. Іноді це може виявитися трудомістким заняттям, але очікуваний ефект того вартий. Головна складність тут - це адаптація перенесеного з індикаторів коду. Адже він зовсім не розрахований на те, щоб працювати в коді іншого індикатора.
Основні проблеми, які при цьому виникнуть:
- Конфлікт імен. Збігаються імена змінних, функцій, особливо системних (OnCalculate, наприклад);
- Відсутність буферів. У деяких індикаторах це може стати непереборною перешкодою для адаптації, якщо логіка індикаторів тісно зав'язана саме на буферне зберігання / обробку даних. Заміна буферів на прості масиви в нашому випадку не вихід, тому що наша мета - зниження витрати пам'яті. Нам важливий саме повна відмова від зберігання в пам'яті будь-якої гігантської історії.
Продемонструю далі прийоми, що дозволяють ефективно вирішити ці проблеми.
Потрібно кожен допоміжний індикатор оформити у вигляді класу. Тоді всі змінні і функції індикаторів матимуть (всередині своїх класів) унікальні імена і не будуть конфліктувати з іншими індикаторами.
Якщо індикаторів переноситься багато, то має сенс також потурбуватися стандартизацією цих класів, щоб потім не плутатися в роботі з ними. Для цих цілей потрібно створити який-небудь базовий індикаторний клас, а класи всіх допоміжних індикаторів успадкувати від нього.
Я написав ось такий клас:
class CIndicator {protected: string symbol; ENUM_TIMEFRAMES timeframe; double Open [], High [], Low [], Close []; int BufLen; public: void Create (string sym, ENUM_TIMEFRAMES tf) {symbol = sym; timeframe = tf;}; void Init (); void Calculate (datetime start_time); }; Тепер на його основі почнемо створювати клас для індикатора Ichimoku. Насамперед пропишемо в ньому у вигляді властивостей вхідні параметри індикатора з точно такими ж іменами, як в оригіналі. Щоб в коді індикатора не треба було потім що-небудь міняти:
Збережемо і назви всіх буферів. Так, ви не помилилися, ми оголосимо всі 5 буферів цього індикатора. Але вони будуть не справжні. Вони будуть складатися всього з одного бару кожен:
public: double ExtTenkanBuffer [1]; double ExtKijunBuffer [1]; double ExtSpanABuffer [1]; double ExtSpanBBuffer [1]; double ExtChinkouBuffer [1]; Для чого це було зроблено? Для того, щоб менше змін потім вносити в код. Зараз побачите. Перевизначити успадкований метод CIchimoku.Calculate, заповнивши його перенесеним з Ichimoku кодом функції OnCalculate.
Зверніть увагу, що при перенесенні з цієї функції був видалений цикл по барам історії, і там тепер розраховується за все один бар до заданого часу. А основний розрахунковий код при цьому залишився незмінним. Ось для чого ми так прискіпливо зберігали все імена буферів і параметрів індикатора.
Зверніть також увагу, що на самому початку методу Calculate заповнюються значеннями цінові буфери. Там рівно стільки значень, скільки знадобиться при розрахунку одного бару.
void Calculate (datetime start_time) {CopyHigh (symbol, timeframe, start_time, BufLen, High); CopyLow (symbol, timeframe, start_time, BufLen, Low); CopyClose (symbol, timeframe, start_time, 1, Close); int i = 0; {ExtChinkouBuffer [i] = Close [i]; double high = Highest (High, InpTenkan, i); double low = Lowest (Low, InpTenkan, i); ExtTenkanBuffer [i] = (high + low) / 2.0; high = Highest (High, InpKijun, i); low = Lowest (Low, InpKijun, i); ExtKijunBuffer [i] = (high + low) / 2.0; ExtSpanABuffer [i] = (ExtTenkanBuffer [i] + ExtKijunBuffer [i]) / 2.0; high = Highest (High, InpSenkou, i); low = Lowest (Low, InpSenkou, i); ExtSpanBBuffer [i] = (high + low) / 2.0; }}; Звичайно, можна було не турбуватися про збереження оригінального коду. Але тоді щоб перенести його, довелося б його сильно переробляти, а для цього потрібно було б розбиратися в його логіці роботи. У нашому випадку індикатор досить простий, і розібратися було б легко. Але уявіть, що було б, потрап нам індикатор складніше? Я показав вам прийом, який вам допоміг би в такому випадку.
Тепер заповнимо метод CIchimoku.Init, в ньому все просто:
void Init (int Tenkan = 9, int Kijun = 26, int Senkou = 52) {InpTenkan = Tenkan; InpKijun = Kijun; InpSenkou = Senkou; BufLen = MathMax (MathMax (InpTenkan, InpKijun), InpSenkou); }; В індикаторі Ichimoku є ще дві функції, які теж потрібно перенести в клас CIchimoku: Highest і Lowest. Вони шукають максимальне і мінімальне значення на заданому фрагменті цінових буферів.
Цінові буфери у нас тепер не справжні, у них дуже короткий розмір (ви бачили їх заповнення в методі Calculate вище), тому потрібно трохи змінити логіку роботи функцій Highest і Lowest.
Тут я теж дотримувався принципу мінімальної правки, всі зміни полягають в додаванні одного рядка, яка, по суті, змінює нумерацію барів в буфері з глобальної (коли буфер довжиною у всю доступну історію) в локальну (адже у нас в цінових буферах тепер лише стільки значень , скільки необхідно для розрахунку одного індикаторного бару):
Метод Lowest модифікується аналогічним чином.
З індикатором Price_Channel теж робляться схожі зміни, тільки він вже буде представлений у вигляді класу з ім'ям CChannel. Повністю обидва класу ви можете побачити в Trender-Include, доданому до статті.
Я описав основні моменти перенесення коду. Думаю, в більшості індикаторів цих прийомів виявиться досить.
Індикатори з нестандартними настройками можуть представляти додаткову складність. Наприклад, в тому ж Price_Channel є непримітні рядки:
PlotIndexSetInteger (0, PLOT_SHIFT, 1); PlotIndexSetInteger (1, PLOT_SHIFT, 1); Вони означають, що графік індикатора зрушать на 1 бар. У нашому випадку це призводить до того, що, наприклад, функції CopyBuffer и CopyHigh звертаються до двох різних барах, незважаючи на те, що координати бару (його час) задані в їх параметрах однакові.
У Trender-Include ця проблема вирішена (в класі CChannel додані "одинички" де потрібно, на відміну від класу CIchimoku, де такої проблеми не було), так що якщо вам теж потрапить подібний підступний індикатор, ви знаєте, де шукати підказку.
Отже, з перенесенням ми закінчили, і обидва допоміжних індикатора знаходяться тепер у вигляді двох класів всередині індикатора Trender-Include. Залишилося нам змінити тільки звернення до цими індикаторами. У Trender у нас були масиви хендлов, а в Trender-Include їх замінять масиви об'єктів:
CIchimoku o_Ichimoku [5]; CChannel o_Channel [5];Створення всіх допоміжних індикаторів в OnInit тепер стане виглядати так:
for (int itf = 0; itf <5; itf ++) {o_Ichimoku [itf] .Create (Symbol (), TF [itf]); o_Ichimoku [itf] .Init (9, 26, 52); o_Channel [itf] .Create (Symbol (), TF [itf]); o_Channel [itf] .Init (22); }А в OnCalculate на зміну CopyBuffer прийде пряме звернення до властивостей об'єктів:
o_Ichimoku [itf] .Calculate (Time); double Tenkan = o_Ichimoku [itf] .ExtTenkanBuffer [0]; double Kijun = o_Ichimoku [itf] .ExtKijunBuffer [0]; if (Tenkan> Kijun) Signal ++; if (Tenkan <Kijun) Signal--; o_Channel [itf] .Calculate (Time); double Mid = o_Channel [itf] .ExtMiddBuffer [0]; if (Price> Mid) Signal ++; if (Price <Mid) Signal--;Мінус 40 буферів. Не дарма ми попрацювали.
Після кожної переробки індикатора Trender описаними раніше способами "Need" і "Aggregate", я тестував вийшов індикатор в візуальному режимі.
Проведемо такий тест і зараз: відкриємо на одному графіку вихідний індикатор (Trender) і перероблений (Trender-Include). Можна зробити висновок, що перероблено все було правильно, тому що лінії обох індикаторів точно збігаються один з одним:
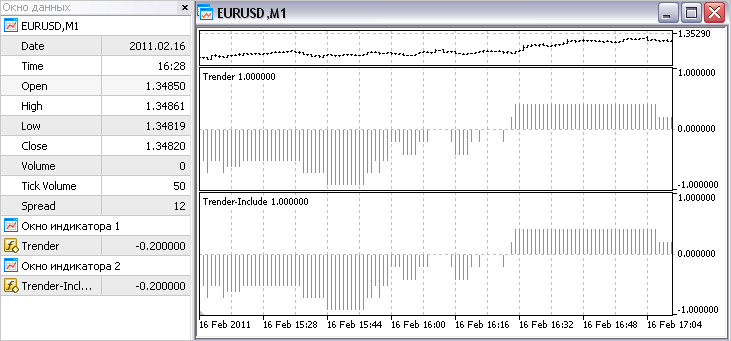
5.4. Чи можна по одному?
Ми розглянули вже 3 способи зменшити кількість буферів допоміжних індикаторів. Але що якщо спробувати кардинально змінити підхід - і зменшувати не загальне кількість буферів, а кількість буферів, що одночасно знаходяться в пам'яті? Тобто, не відразу все індикатори завантажувати в пам'ять, а по одному. Організувати таку собі "карусель": створили один допоміжний індикатор, прочитали з нього дані, видалили, створили наступний і т.д., і так перебирати таймфрейм за таймфрейме. Найбільше буферів у індикатора Ichimoku - 5 штук. Значить, теоретично, в кожен момент часу в пам'яті могло б перебувати не більше 5 буферів (плюс 1 буфер головного індикатора), і загальна економія склала б 35 буферів!
Чи це можливо? У MQL5 адже навіть і функція є для видалення індикаторів - IndicatorRelease .
Але, не всі тут так просто, як здається. MetaTrader 5 піклується про високу швидкість роботи MQL5-програм, тому будь-які таймсеріі, до яких було звернення, кешуються в пам'яті - раптом вони знадобляться якомусь ще індикатору, експерту або скрипту. І тільки якщо тривалий час ніхто не буде повторно запитувати ці дані, тоді вони вивантажили, звільнивши пам'ять. Це час очікування становить до 30 хвилин.
Так що, постійне створення-видалення індикаторів не дозволить досягти великий миттєвої економії пам'яті. Зате, що дуже важливо, здатне серйозно уповільнити роботу комп'ютера - адже при кожному створенні індикатора він розраховується на всій історії. Подумайте, наскільки буде доцільним проробляти таке на кожному історичному барі головного індикатора ...
Проте, ідея з "індикаторної каруселлю", безсумнівно, була цікавою - в контексті "мозкового штурму". Якщо ви придумаєте якісь ще незвичайні ідеї оптимізації пам'яті індикаторів, пишіть в коментарях до статті - можливо, вони знайдуть своє теоретичне або практичне розгляд в одній з наступних статей на цю тему.
6. Вимірюємо реальний витрата пам'яті
Отже, в попередніх розділах ми реалізували 3 працюючих способу зменшення кількості буферів допоміжних індикаторів. Давайте тепер подивимося, наскільки це дозволяє зменшити реальний витрата пам'яті.
Вимірювати об'єм зайнятої терміналом пам'яті будемо за допомогою "Диспетчера завдань" Windows. На вкладці "Процеси" там видно, скільки термінал займає оперативної і віртуальної пам'яті. например:
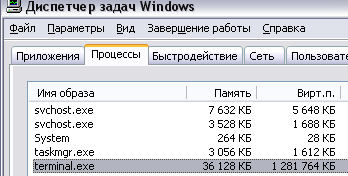
Вимірювання проводяться за наступним алгоритмом, що дозволяє побачити мінімальний витрата пам'яті терміналом (це і буде близько до безпосереднього витраті пам'яті індикаторами):
- Викачуємо глибоку історію з сервера MetaQuotes-Demo (досить запустити тестування з символу, щоб історія з нього автоматично скачати);
- Термінал налаштовуємо на чергове вимір (відкриваємо потрібні графіки та індикатори) і перезапускаємо - щоб в пам'яті не залишалося нічого зайвого, крім того, що нам потрібно;
- Чекаємо, поки перезапущена термінал завершить розрахунки всіх індикаторів. Це стане видно за нульовою завантаженні процесора;
- Звертаємо термінал на панель задач (стандартна кнопка Windows "Згорнути" в правому верхньому кутку терміналу) - так він звільняє що не використовується в даний момент для розрахунків оперативну пам'ять (на скріншоті вище якраз приклад витрати оперативної пам'яті в спокійному згорнутому стані - видно, що її може бути зайнято набагато менше в порівнянні з віртуальною);
- В "Диспетчері задач" зчитуємо суму колонок "Пам'ять" (оперативна) і "Вірт.п." (віртуальна пам'ять). Так вони називаються в Windows XP, в інших версіях ОС можуть називатися по-іншому.
Параметри вимірювань:
- Для більшої точності вимірювань, будемо використовувати не один ціновий графік, а відразу всі доступні пари на демо-рахунку MetaQuotes - тобто 22 графіка M1. Потім обчислювати середні значення;
- Налаштування "Макс. Барів у вікні" (описана в розділі 4.1) стандартна - 100000;
- ОС - Windows XP, 32 bit.
Чого очікувати від результатів вимірювань? Зроблю тут два зауваження:
- Хоча індикатор Trender і задіє 41 буфер, це не означає, що він займає 41 * 100000 барів. Адже ці буфери розкинуті по п'яти таймфрейме, і на старших з них барів менше, ніж на молодших. Наприклад, в історії EURUSD на хвилинах загалом понад 4 млн. Барів, а на часовках, відповідно, лише близько 70000 (4000000/60). Тому не варто очікувати, що зменшення числа буферів в Trender призведе до такого ж зниження витрати пам'яті;
- Пам'ять займає не тільки індикатор, але і використовувані ним цінові серії. Trender звертається до п'яти таймфрейме. Це означає, що якщо ми зменшимо число буферів в кілька разів, то загальна витрата пам'яті не зменшиться в стільки ж разів. Тому що цінових серій в пам'яті все одно буде використовуватися 5.
При вимірюванні витрати можуть виявитися і інші чинники, які нам невідомі, але які впливають на споживання пам'яті. Саме для цього ми і проводимо практичні виміри, щоб побачити, якою буде реальна економія від оптимізації індикатора.
Далі представлена таблиця з результатами всіх вимірювань. Спочатку було виміряно, скільки пам'яті споживає порожній термінал. У наступному вимірі, віднімаючи це число, стало можливим визначити, скільки споживає один графік. У наступних вимірах, віднімаючи витрата терміналу і графіка, з'ясувалося, скільки пам'яті доводиться на кожен індикатор.
індикаторних буферів
таймфрейме
Витрата пам'яті Термінал
0
0
38 Mb на термінал Графік
0
1
12 Mb на один порожній графік Індикатор Trender
41
5
46 Mb на один індикатор Індикатор Trender-Need
31
5
42 Mb на один індикатор Індикатор Trender-Aggregate 21
5
37 Mb на один індикатор
Індикатор Trender-Include 1
5
38 Mb на один індикатор
Висновки за результатами вимірювань:
- Зменшення числа індикаторних буферів знижує витрату пам'яті індикатором не у стільки ж разів.
- Перенесення коду всіх допоміжних індикаторів в головний індикатор не завжди є найефективнішим рішенням.
Чому ж спосіб Include не опинився ефективніше способу Aggregate? Щоб визначити причину, потрібно згадати основні відмінності коду цих індикаторів. У Aggregate необхідні для розрахунків цінові серії подаються терміналом як вхідні масиви в OnCalculate, А в Include всі ці дані (для всіх таймфреймів) активно запитуються для кожного бару через CopyHigh , CopyLow , CopyClose . Мабуть, це і призводить до появи додаткових витрат пам'яті, пов'язаних з особливостями кешування цінових серій при використанні цих функцій.
Висновок
Отже, зі статті ви дізналися 3 працюючих способу зниження витрати пам'яті на допоміжні індикатори, і 1 спосіб заощадити пам'ять шляхом настройки терміналу.
Який із способів ви застосуєте в ваших програмах буде залежати від того, які з них виявляться доступними і виправданими у вашій ситуації. Кількість зекономлених буферів і мегабайтів теж буде залежати від індикаторів, які вам попадуться: в якихось можна буде "відрізати" побільше, а в якихось не виявиться нічого зайвого.
Зекономлена пам'ять дозволить вам збільшити число одночасно використовуваних в терміналі валютних пар, індикаторів і стратегій, що підвищить надійність вашого торгового портфеля. Так проста турбота про технічні ресурси вашого комп'ютера може перетворюватися в матеріальні ресурси на вашому депозиті.
додатки
До статті додаються індикатори, описувані в статті. Щоб все працювало, потрібно зберегти їх в папку "MQL5 \ Indicators \ TestSlaveIndicators", тому що всі версії індикатора Trender (крім Trender-Include, звичайно ж) шукають свої допоміжні індикатори в ній.
Як все це вмістити на одному комп'ютері?Але уявіть, що було б, потрап нам індикатор складніше?
Але що якщо спробувати кардинально змінити підхід - і зменшувати не загальне кількість буферів, а кількість буферів, що одночасно знаходяться в пам'яті?
Чи це можливо?
Чого очікувати від результатів вимірювань?
Чому ж спосіб Include не опинився ефективніше способу Aggregate?
